
Post: Introduction to Achieving Concurrency in Python for Faster Network Automation
Throughout the years, I’ve utilized different methods to achieve concurrency in Python. In this article, I will give a few simple examples of how you can speed up your tasks for network automation (or anything really!).
Heads up! The examples include Python’s API for multithreading/multiprocessing, however you may never need to use it. If you are curious or need to implement your own concurrency code, the examples below are for you. If you’d rather use an automation framework, check out nornir. It is an alternative to Ansible where you can write all your automation tasks in pure Python. Engineers praise it’s ease of use and speed.
To make this article short, sweet, and to the point, I’m going to quickly go over a few basic concepts:
Concurrency
- This is efficiently using the resources at hand. Things don’t necessarily have to be done at the same time, but rather tasks can be stopped and resumed while waiting for an I/O event. If you invoke several GET requests to an Arista switch, there will be some network latency involved, processing from the switch itself, etc. Using multithreading in Python will speed up API calls when multiple switches are involved.
Parallelism
- Doing a lot of things at the same time. Imagine an 8 core processor where each core can work on different chunks of data to speed up the overall task. Parallelism can be a way of achieving conccurency.
GIL
- The GIL is a mutex (lock) in CPython that will prevent more than one thread from executing Python bytecodes at once. CPython’s memory management is not thread-safe. This prevents race conditions. The GIL is great for single-threaded applications, but not for multi-threaded once. For example, when you make multiple API calls using multithreading, the GIL will not have much affect. This is because the GIL is shared between threads while they are waiting for I/O. So Python can switch off between threads and do work while waiting for another thread.
- CPU bound programs are more efficiently ran using multi-processing
- I/O bound programs (database, file, network) are more efficiently ran using multi-threading
When you run a multithreading application, you are spawning multiple child threads from a main thread:

If you are ever curious and want to monitor child threads spawned from a script you’ve created, you can run this command (or something similar) right after your program begins:
watch -n .5 'ps aux | grep multi-thread.py | grep -v grep
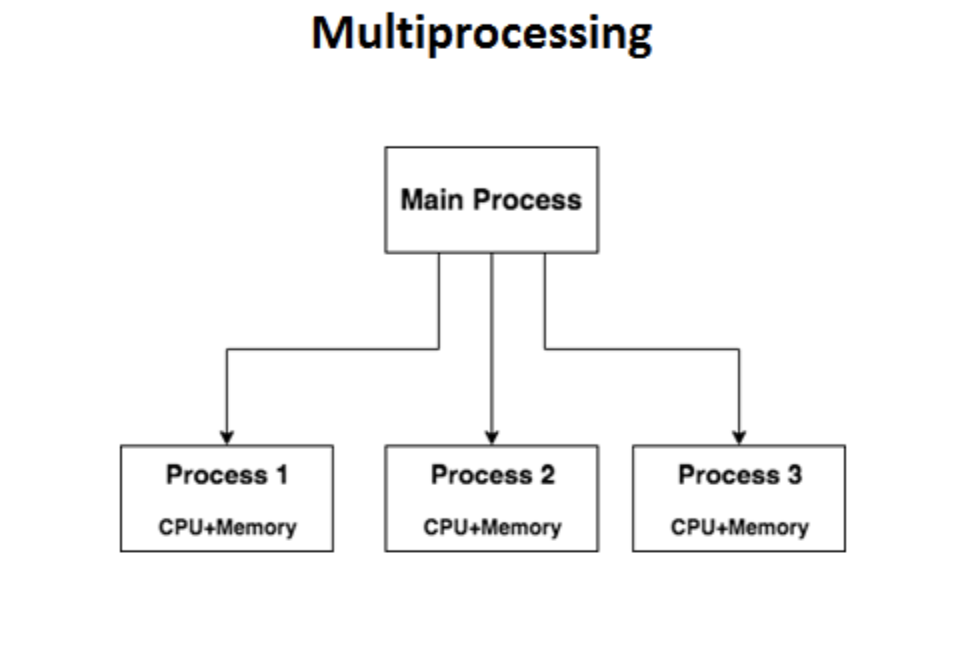
And multiprocessing:
Python now has the Futures library, introduced in 3.2 but has since added many features and changes. This is the
new preferred way of writing multiprocessing/multithreading in code. If you are familiar with Javascript, the concepts
should be very familiar. For example, Future may be thought of as a Promise. We will not be covering Python’s asyncio
library in this post.
Alright, let’s get into the code! We will be using Parmiko to communicate via SSH to a few Cumulus switches set up
in Vagrant. We will not cover the set up of my lab environment in this post. Run pip install parmiko if you do not already have this external library.
Example 1: Multithreading using Python’s multiprocessing.dummy module (Old Way). We use map() to
run the show_system function against each argument in the provided list. map() will return the results in the order
the arguments were received. close() is used to close the pool of workers. join() will wait until the workers
have completed their work.
from multiprocessing.dummy import Pool as Threadpool
import paramiko
import json
def show_system(hostname):
client = paramiko.SSHClient()
client.set_missing_host_key_policy(paramiko.AutoAddPolicy())
client.connect(
hostname=hostname,
username='cumulus',
password='CumulusLinux!',
look_for_keys=False,
allow_agent=False,
timeout=5
)
# show system information
_, stdout, stderr = client.exec_command('net show system json')
stdout = stdout.read().decode('utf-8')
structured_show_system_output = json.loads(stdout)
return structured_show_system_output
host_ips = ['192.168.1.26', '192.168.1.27', '192.168.1.28']
pool = Threadpool(16)
results = pool.map(show_system, host_ips)
pool.close()
pool.join()
Note: Functions need to be pickleable. Python exchange objects via pickles. This converts python objects to byte-strings and vice versa - it serializes/deserializes. Functions inside other functions can’t work, things like generators don’t work, etc.
Example 2: Multithreading using the Python Futures API (New Way)
from concurrent import futures
with futures.ThreadPoolExecutor(max_workers=16) as pool:
results = [pool.submit(show_system, host_ip) for host_ip in host_ips]
for future in futures.as_completed(results): # as_completed will return results as you get them
data = future.result()
print(data)
Additionally, you can guarantee results are returned in the order the arguments were passed by using map()
with futures.ThreadPoolExecutor(max_workers=16) as pool:
for future in pool.map(show_system, host_ips):
print(future)
Note: You can input multiple arguments per element in iterable by providing pool.map() with more than one iterable
Note: There is a default for the max_workers argument that is a formula that seemigly changes every new release
of Python :-)
Using wait() to wait for all futures to be fulfilled
pool = futures.ThreadPoolExecutor(max_workers=16)
f = [pool.submit(show_system, host_ip) for host_ip in host_ips]
print(futures.wait(f))
Example 4: Implement Multiprocessing using the Futures API
Normally, you may have to use something like manager to share a list or another data-type between processes.
Here, we share the counter variable between processes
import time
import random
# we need to simulate some sort of CPU intensive work here, so we use time.sleep()
def do_something_interesting(i):
time.sleep(1)
return random.randint(0, 100000) + i
counter = int()
with futures.ProcessPoolExecutor(max_workers=8) as pool:
submits = [pool.submit(do_something_interesting, x) for x in range(0, 4)]
for i in futures.as_completed(submits):
r = i.result() # you can use the timeout kwarg in result to wait a certain time before moving on
counter += 1
print(r)
print(counter)
As processes are worked on, they will update the counter.
Pretty easy right? That’s the beauty and power of Python. I plan on migrating code to use the Futures API which provides
an even easier way to access concurrency. Leave a comment below and let me know what you think!
More on the GIL: GIL
Concurrency Vs. Parallelism: concurrency-vs-parallelism
Comments